SQLiteStudio
月度归档:2023年10月
Paypal支付
PayPal收款,其它结汇。
1.Pingpong
2.连连
3.空中云汇
4.WF万里汇 据说这是阿里旗下的?
5.寻汇
6.易鲸跨境
https://zhuanlan.zhihu.com/p/447230015
提现尽量小额高频度,小额低风险,大额高风险。
https://www.zhihu.com/question/507386319/answer/3197892771

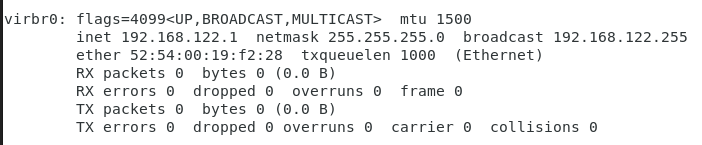
测试网卡并禁用virbr0网卡
利用vmware动态修改网卡,实现系统内IP地址的修改。
sudo systemctl start libvirtd.service 如果系统没有启动,
sudo systemctl stop libvirtd.service 仍然后获取该网卡的状态。
sudo systemctl disable libvirtd.service 禁用随系统启动,操作此项后,重启系统生效。
systemctl mask libvirtd.service 慎用,真的会删除,且无法恢复。
FBX被Qt调用库
https://www.autodesk.com/developer-network/platform-technologies/fbx-sdk-archives
———————–
https://www.autodesk.com/developer-network/platform-technologies/fbx-sdk-2020-3-4
https://www.autodesk.com/content/dam/autodesk/www/adn/fbx/2020-3-4/fbx202034_fbxsdk_vs2017_win.exe
https://www.autodesk.com/content/dam/autodesk/www/adn/fbx/2020-3-4/fbx202034_fbxsdk_linux.tar.gz
————————————————–
https://www.autodesk.com/developer-network/platform-technologies/fbx-sdk-2019-5
https://www.autodesk.com/content/dam/autodesk/www/adn/fbx/20195/fbx20195_fbxsdk_vs2017_win.exe
https://www.autodesk.com/content/dam/autodesk/www/adn/fbx/20195/fbx20195_fbxsdk_linux.tar.gz
VIM操作时自动缩进的解决方案
VIM在粘贴时,会根据当前文件类型而采用不同地缩进方案,如编辑yaml文件,从而导致以下混乱,如下图示:
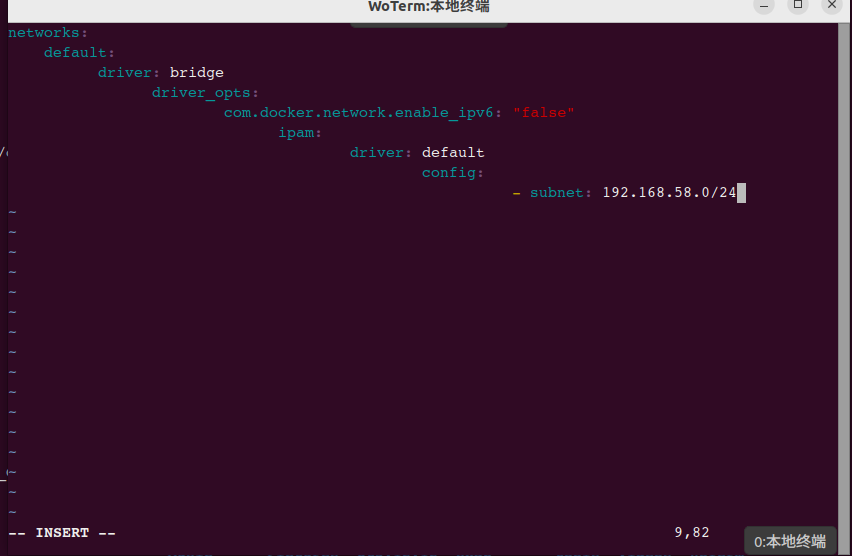
解决此问题方法如下:
:set paste #这方式是表示进行粘贴模式,则可以实现正常的粘贴效果了。
#启用模式时,在下方明确显示(paste)字样。
:set nopaste #取消粘贴模式,恢复之前的缩进效果。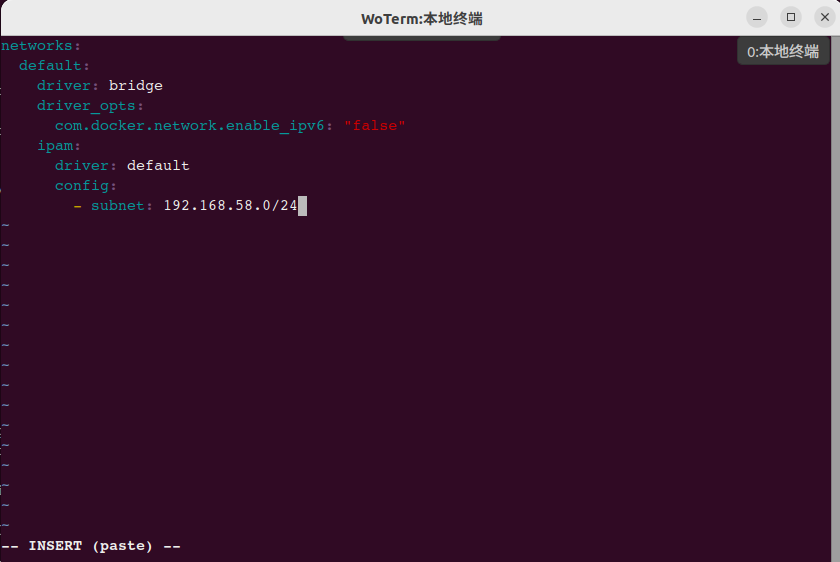
AI显卡
支持ITX主板的3050显卡,1700元
GeForce RTX 3050显卡的单精度浮点性能为9T FLOPS,大概18个Tops
https://item.jd.com/10077097937039.html#crumb-wrap
—-====================
大模型(Large Model)是指具有数百万或数十亿个参数的深度神经网络模型,这种模型经过专门的训练过程,能够对大规模数据进行复杂的处理和任务处理。
大模型需要占用大量的计算资源、存储空间、时间和电力等资源来保证它的训练和部署。相比之下,小模型(Small Model)是指具有较少参数的深度神经网络模型。小模型常常运行速度更快,也更加轻便,适用于一些计算资源和存储空间较少的设备或场景,例如移动设备或嵌入式设备。
===========================
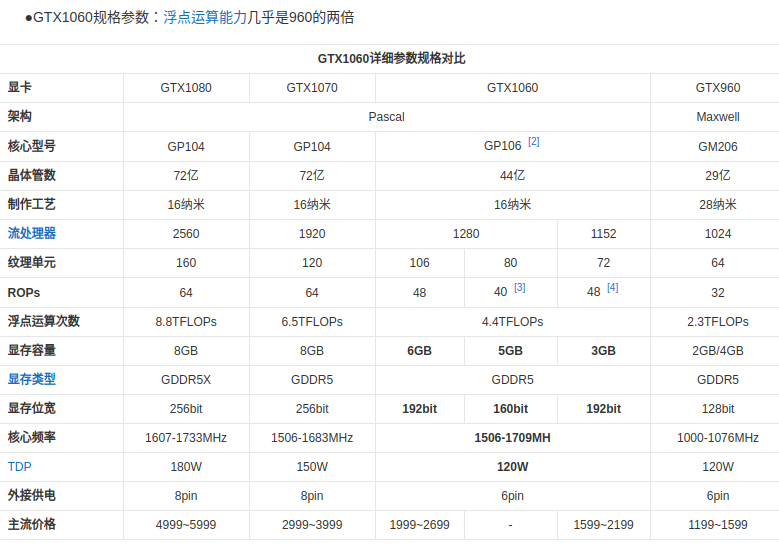
AI应学习应用阶段,一般需要八代酷睿I5或三代锐龙R5以上处理器、16G以上内存、GTX1060以上独立显卡。
GTX 1060的理论浮点运算性能为4.4 TFLOPS
=============================
RTX 3080 Ti的算力确实比GTX 1060更高。根据Nvidia官方数据,RTX 3080 Ti的理论浮点运算性能(FP32)为34.1 TFLOPS
===============================
2016年的信息
https://baike.baidu.com/item/GTX1060/19888890?fr=ge_ala
FLOPS和TOPS的区别 以及 算力的计算方法
TFLOPs和 TOPs都是描述深度学习设备计算能力的单位,1TFLOPS与1TOPS,前者代表是每秒执行1万亿次 浮点 运算次数,后者代表每秒执行1万亿次运算次数,区别FL即float浮点,大多数NPU都是定点运算,故通TOPS来标称算力。它们之间的转换通常可以用(1太拉)1TFLOPS=2*1TOPS来计算,但是需要注意TFLOPS中有单精度FP32 和半精度FP16的区别,默认是FP16。
理论峰值 = GPU芯片数量GPU Boost主频核心数量*单个时钟周期内能处理的浮点计算次数
只不过在GPU里单精度和双精度的浮点计算能力需要分开计算,以最新的Tesla P100为例:
双精度理论峰值 = FP64 Cores * GPU Boost Clock * 2 = 1792 *1.48GHz*2 = 5.3 TFlops
单精度理论峰值 = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.58GHz * 2 = 10.6 TFlop
单精度计算能力的峰值 = 单核单周期计算次数 × 处理核个数 × 主频
算力单位
TOPS(Tera Operations Per Second:)1TOPS处理器每秒钟可进行一万亿次(10^12)操作。
GOPS(Giga Operations Per Second):1GOPS处理器每秒钟可进行一亿次(10^9)操作。
MOPS(Million Operation Per Second):1MOPS处理器每秒钟可进行一百万次(10^6)操作。
如下表示FLOPS,分别以M,G,T,P四种级别来表示,当然你也可以用到TOPS上面
一个MFLOPS(megaFLOPS)等于每秒一百万(=10^6)次的浮点运算,
一个GFLOPS(gigaFLOPS)等于每秒十亿(=10^9)次的浮点运算,
一个TFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算,(1太拉)
一个PFLOPS(petaFLOPS)等于每秒一千万亿(=10^15)次的浮点运算,
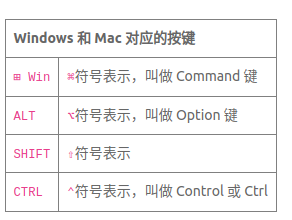
Windows和Mac对应的按键
Win键对应用Command键
Alt键对应Option键
CTRL对应Control键