dstat -tamsl
dstat 是一个可以取代vmstat,iostat,netstat和ifstat这些命令的多功能产品。dstat克服了这些命令的局限并增加了一些另外的功能,增加了监控项,也变得更灵活了。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。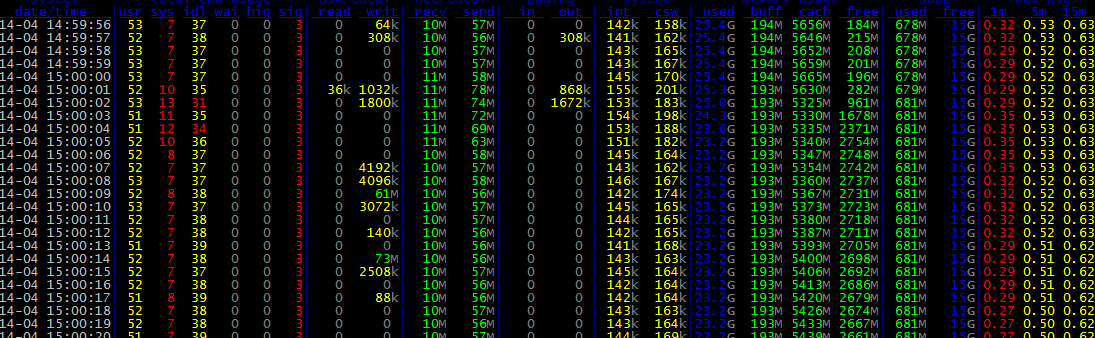
ethtool eth0查网卡信息
dstat -tamsl
dstat 是一个可以取代vmstat,iostat,netstat和ifstat这些命令的多功能产品。dstat克服了这些命令的局限并增加了一些另外的功能,增加了监控项,也变得更灵活了。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。
ethtool eth0查网卡信息
https://dev.mysql.com/doc/refman/5.7/en/resetting-permissions.html
http://blog.chinaunix.net/uid-23464606-id-4951847.html
http://litaotao.blog.51cto.com/6224470/1301509?utm_source=tuicool&utm_medium=referral
看到论坛中的一段介绍,感觉豁然开即朗的感觉,简单总结一下:
从个人感觉:外网IP就是真实IP,而内网IP或局域网IP就是虚拟IP。
以下是摘录别人的:
动态 IP 、固定 IP 、实体 IP 与虚拟 IP都讲解一下,加深理解和知识扩展
实体 IP:在网络的世界里,为了要辨识每一部计算机的位置,因此有了计算机 IP 位址的定义。一个 IP 就好似一个门牌!例如,你要去微软的网站的话,就要去『 207.46.197.101 』这个 IP 位置!这些可以直接在网际网络上沟通的 IP 就被称为『实体 IP 』了。
虚拟 IP:不过,众所皆知的,IP 位址仅为 xxx.xxx.xxx.xxx 的资料型态,其中, xxx 为 1-255 间的整数,由于近来计算机的成长速度太快,实体的 IP 已经有点不足了,好在早在规划 IP 时就已经预留了三个网段的 IP 做为内部网域的虚拟 IP 之用。这三个预留的 IP 分别为:
A级:10.0.0.0 – 10.255.255.255
B级:172.16.0.0 – 172.31.255.255
C级:192.168.0.0 – 192.168.255.255
上述中最常用的是192.168.0.0这一组。不过,由于是虚拟 IP ,所以当您使用这些地址的时候﹐当然是有所限制的,限制如下:
私有位址的路由信息不能对外散播
使用私有位址作为来源或目的地址的封包﹐不能透过Internet来转送
关于私有位址的参考纪录(如DNS)﹐只能限于内部网络使用
由于虚拟 IP 的计算机并不能直接连上 Internet ,因此需要特别的功能才能上网。不过,这给我们架设IP网络做成很大的方便﹐比如﹕即使您目前的公司还没有连上Internet﹐但不保证将来不会啊。如果使用公共IP的话﹐如果没经过注册﹐等到以后真正要连上网络的时候﹐就很可能和别人冲突了。也正如前面所分析的﹐到时候再重新规划IP的话﹐将是件非常头痛的问题。这时候﹐我们可以先利用私有位址来架设网络﹐等到真要连上intetnet的时候﹐我们可以使用IP转换协定﹐如 NAT (Network Addresss Translation)等技术﹐配合新注册的IP就可以了。
固定 IP 与 动态 IP:基本上,这两个东西是由于近来网络公司大量的成长下的产物,例如,你如果向中华电信申请一个商业型态的 ADSL 专线,那他会给你一个固定的实体 IP ,这个实体 IP 就被称为『固定 IP 』了。而若你是申请计时制的 ADSL ,那由于你的 IP 可能是由数十人共同使用,因此你每次重新开机上网时,你这部计算机的 IP 都不会是固定的!于是就被称为『动态 IP』或者是『浮动式IP』。基本上,这两个都是『实体IP』,只是网络公司用来分配给用户的方法不同而产生不同的名称而已
修改最后一次提交记录。
git commit --amend
——————————————-
修改最近第N次记录。
1.rebase到需要修改的注释
$ git rebase -i HEAD~5
2.显示形式如下:
pick e0b2e6e [PLCS#1201612060035]for: 增加异常处理dfdsfsdfsdfdsfjkksdjfs
pick 4df06f8 [PLCS#1201612060035]for: [PLCS#1201612060035]for: 增加了与
如果显示有错误如下,则需要按提示执行 git stash。
Cannot rebase: You have unstaged changes.
Please commit or stash them.
3.使用vi命令,把pick字符串修改为edit,并保存。
pick e0b2e6e [PLCS#1201612060035]for: 增加异常处理dfdsfsdfsdfdsfjkksdjfs
edit 4df06f8 [PLCS#1201612060035]for: [PLCS#1201612060035]for: 增加了与
4.再次执行以下命令
git commit --amend
5.修改好注释后。执行以下命令,完成注释修改。
git rebase --continue
6.git log检查。
1.在~/cluster/zookeeper目录下,安装3份zookeeper程序副本,分别命名为server1,server2,server3
2.执行以下命令。
cp server1/conf/zoo_sample.cfg server1/conf/zoo.cfg
3.在zoo.cfg文件中添加如下命令
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/abc/cluster/zookeeper/data/server1/data
dataLogDir=/home/abc/cluster/zookeeper/data/server1/log
clientPort=2181
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
4.因为是伪集群,故另外两份必须如下设置。
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/abc/cluster/zookeeper/data/server2/data
dataLogDir=/home/abc/cluster/zookeeper/data/server2/log
clientPort=2182
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/abc/cluster/zookeeper/data/server3/data
dataLogDir=/home/abc/cluster/zookeeper/data/server3/log
clientPort=2183
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
5.执行余下这些命令
mkdir -p /home/abc/cluster/zookeeper/data/server1/data
mkdir -p /home/abc/cluster/zookeeper/data/server2/data
mkdir -p /home/abc/cluster/zookeeper/data/server3/data
echo "1" > /home/abc/cluster/zookeeper/data/server1/data/myid
echo "2" > /home/abc/cluster/zookeeper/data/server2/data/myid
echo "3" > /home/abc/cluster/zookeeper/data/server3/data/myid
6.启动集群
cd ~/cluster/zookeeper
server1/bin/zkServer.sh start
server2/bin/zkServer.sh start
server3/bin/zkServer.sh start
四层负载均衡指的是负载均衡设备通过报文中的目标IP地址和端口负载均衡算法,选择到达目的的内部服务器;
七层负载均衡,也被称为“内容交换”,指的是负载均衡设备通过报文中的应用层信息(URL、HTTP头部等信息)和负载均衡算法,选择到达目的的内部服务器。
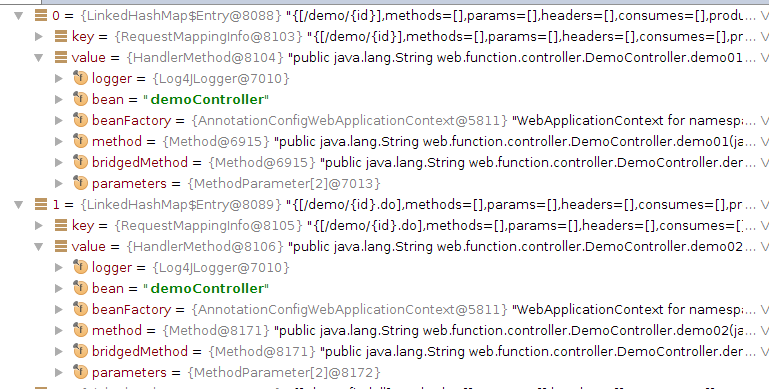
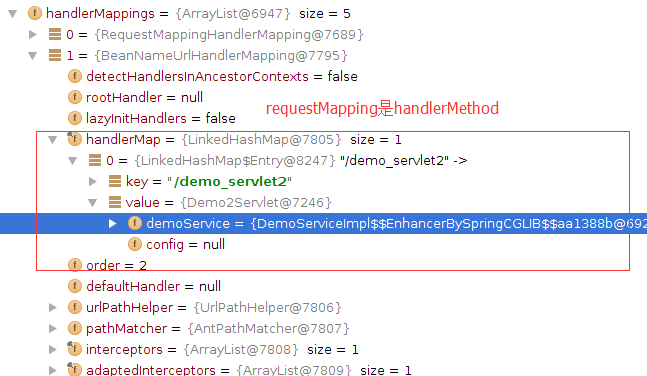
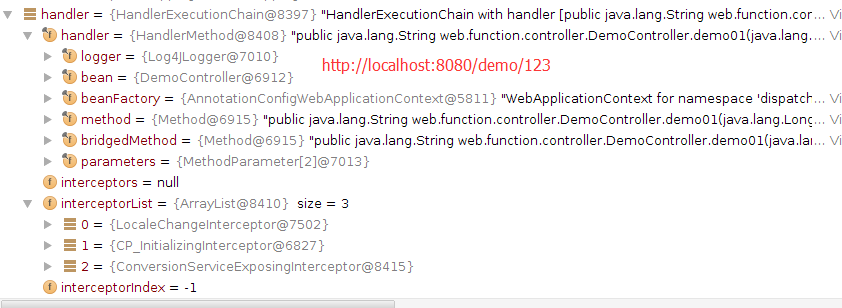
1.当处理一个URL请求时,将会在DispatcherServlet模块中,循环获取相应的处理Handler。如下图:
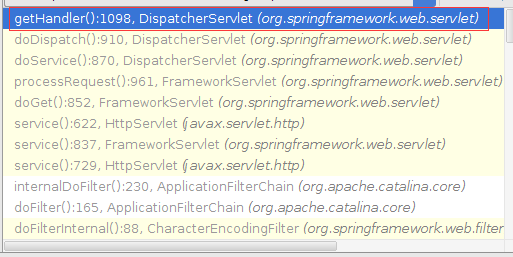
2.getHandler的关键函数
protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
Iterator var2 = this.handlerMappings.iterator();
HandlerExecutionChain handler;
do {
if(!var2.hasNext()) {
return null;
}
HandlerMapping hm = (HandlerMapping)var2.next();
if(this.logger.isTraceEnabled()) {
this.logger.trace("Testing handler map [" + hm + "] in DispatcherServlet with name \'" + this.getServletName() + "\'");
}
//通过遍历比较,
handler = hm.getHandler(request);
} while(handler == null);
return handler;
}
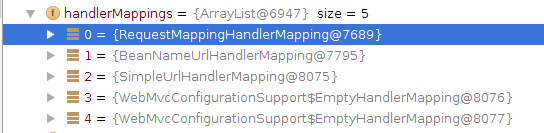
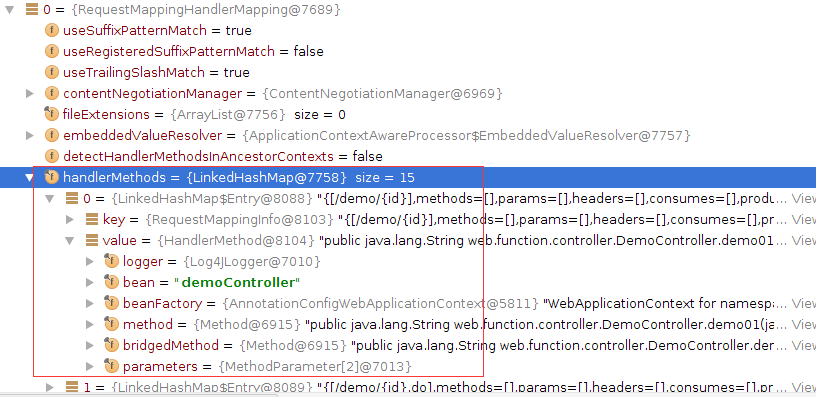
3.getHandler中的局部变量


Apache Eagle:分布式实时 Hadoop 数据安全方案
因为是ebay电商公司的开源,所以它更适合电商平台的使用。
———————————————————-
Eagle Architecture
数据流接入和存储(Data Collection and Storage)
Eagle 提供高度可扩展的编程API,可以支持将任何类型的数据源集成到Eagle的策略执行引擎中。例如,在Eagle HDFS 审计事件(Audit)监控模块中,通过Kafka来实时接收来自Namenode Log4j Appender 或者 Logstash Agent 收集的数据;在Eagle Hive 监控模块中,通过YARN API 收集正在运行Job的Hive 查询日志,并保证比较高的可伸缩性和容错性。
数据实时处理(Data Processing)
流 处理API(Stream Processing API)Eagle 提供独立于物理平台而高度抽象的流处理API,目前默认支持Apache Storm,但是也允许扩展到其他任意流处理引擎,比如Flink 或者 Samza等。该层抽象允许开发者在定义监控数据处理逻辑时,无需在物理执行层绑定任何特定流处理平台,而只需通过复用、拼接和组装例如数据转换、过滤、 外部数据Join等组件,以实现满足需求的DAG(有向无环图),同时,开发者也可以很容易地以编程地方式将业务逻辑流程和Eagle 策略引擎框架集成起来。Eagle框架内部会将描述业务逻辑的DAG编译成底层流处理架构的原生应用,例如Apache Storm Topology 等,从事实现平台的独立。
1.vim配置文件和插件
https://github.com/ma6174/vim
2.vim自动化插件,非常著名,包括了各种各样的插件,貌似没有for gdb的插件。
http://vim.spf13.com/
3.https://github.com/wklken/k-vim
4.https://github.com/fisadev/fisa-vim-config