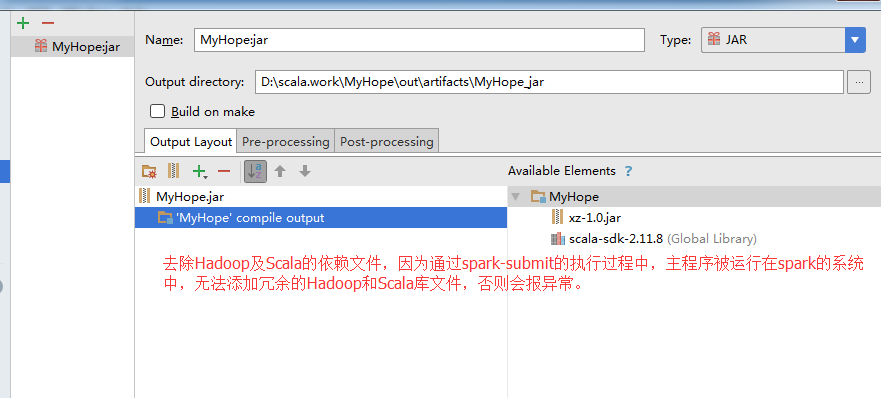
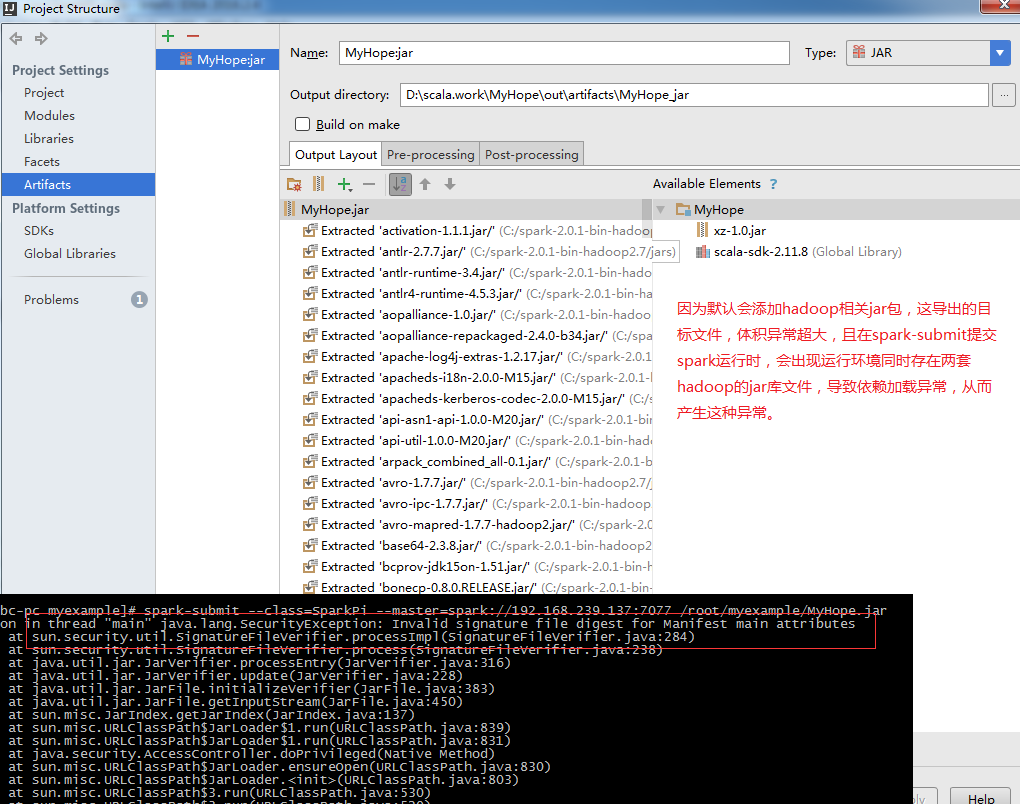
一、 Hadoop伪分布配置
- 在conf/Hadoop-env.sh文件中增加:export JAVA_HOME=/home/Java/jdk1.6
- 在conf/core-site.xml文件中增加如下内容:
<!– fs.default.name – 这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。–>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<!—hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中–>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/tmp</value>
</property>
- 在conf/hdfs-site.xml中增加如下内容:
<!– dfs.replication -它决定着 系统里面的文件块的数据备份个数。对于一个实际的应用,它 应该被设为3(这个 数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的 可靠性(系统故障时,也许会造成数据丢失)–>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!– dfs.data.dir – 这是DataNode结点被指定要存储数据的本地文件系统路径。DataNode结点上 的这个路径没有必要完全相同,因为每台机器的环境很可能是不一样的。但如果每台机器上的这 个路径都是统一配置的话,会使工作变得简单一些。默认的情况下,它的值hadoop.tmp.dir, 这 个路径只能用于测试的目的,因为,它很可能会丢失掉一些数据。所以,这个值最好还是被覆 盖。
dfs.name.dir – 这是NameNode结点存储hadoop文件系统信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用到它。上面对于/temp类型的警告,同样也适用于这里。在实际应用中,它最好被覆盖掉。–>
<property>
<name>dfs.name.dir</name>
<value>/home/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdfs/data</value>
</property>
<!—解决:org.apache.hadoop.security.AccessControlException:Permission denied:user=Administrator,access=WRITE,inode=”tmp”:root:supergroup:rwxr-xr-x 。
因为Eclipse使用hadoop插件提交作业时,会默认以 DrWho 身份去将作业写入hdfs文件系统中,对应的也就是 HDFS 上的/user/hadoop , 由于 DrWho 用户对hadoop目录并没有写入权限,所以导致异常的发生。解决方法为:放开 hadoop 目录的权限, 命令如下 :$ hadoop fs -chmod 777 /user/hadoop –>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>
If “true”, enable permission checking in HDFS. If “false”, permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode, owner or group of files or directories
</description>
</property>
- 在conf/mapred-site.xml中增加如下内容:
<!– mapred.job.tracker -JobTracker的主机(或者IP)和端口。–>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
二、操作命令
- 格式化工作空间
进入bin目录,运行 ./hadoop namenode –format
- 启动hdfs
进入hadoop目录,在bin/下面有很多启动脚本,可以根据自己的需要来启动。
* start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的Hadoop
* start-mapred.sh 启动Map/Reduce守护。包括Jobtracker和Tasktrack
* stop-mapred.sh 停止Map/Reduce守护
* start-dfs.sh 启动Hadoop DFS守护Namenode和Datanode
* stop-dfs.sh 停止DFS守护
三、Hadoop hdfs 整合
可按如下步骤删除和更改hdfs不需要的文件:
1.将hadoop-core-1.0.0.jar 移动到lib目录下。
- 将ibexec目录下的文件移动到bin目录下。
- 删除除bin、lib、conf、logs之外的所有目录和文件。
- 如果需要修改日志存储路径,则需要在conf/hadoop-env.sh文件中增加:
export HADOOP_LOG_DIR=/home/xxxx/xxxx即可。
四、HDFS文件操作
Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。
- 查看文件列表
查看hdfs中/user/admin/hdfs目录下的文件。
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs -ls /user/admin/hdfs
查看hdfs中/user/admin/hdfs目录下的所有文件(包括子目录下的文件)。
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs -lsr /user/admin/hdfs
- 创建文件目录
查看hdfs中/user/admin/hdfs目录下再新建一个叫做newDir的新目录。
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs -mkdir /user/admin/hdfs/newDir
- 删除文件
删除hdfs中/user/admin/hdfs目录下一个名叫needDelete的文件
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs -rm /user/admin/hdfs/needDelete
删除hdfs中/user/admin/hdfs目录以及该目录下的所有文件
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs -rmr /user/admin/hdfs
- 上传文件
上传一个本机/home/admin/newFile的文件到hdfs中/user/admin/hdfs目录下
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs –put /home/admin/newFile /user/admin/hdfs/
- 下载文件
下载hdfs中/user/admin/hdfs目录下的newFile文件到本机/home/admin/newFile中
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs –get /user/admin/hdfs/newFile /home/admin/newFile
- 查看文件内容
查看hdfs中/user/admin/hdfs目录下的newFile文件
- 进入HADOOP_HOME目录。
- 执行sh bin/hadoop fs –cat /home/admin/newFile